PDFをOCRに変換する方法
ハード コピー ドキュメントをスキャンして PDF 形式に保存すると、コンピューターはスキャンしたテキストのページと写真の違いを認識しません。したがって、ページ上のテキストを検索または選択してコピー アンド ペーストすることはできません。テキストを検索または選択する場合は、ドキュメントに対して光学式文字認識 (OCR) を実行する必要があります。 Adobe Acrobat Professional にはこの機能がありますが、Adobe Acrobat の無償版にはありません。 Acrobat Professional をお持ちでない場合は、PDF ドキュメントで OCR を実行するための Acrobat Professional 以外のソフトウェアが存在し、Web を検索して見つけることができることに注意してください。
ステップ 1
Adobe Acrobat Professional をロードします。 Acrobat Professional の OCR 機能は Web ブラウザー プラグインからは利用できないため、実際のプログラムをロードする必要があります。
ステップ 2
コピーおよび貼り付けを選択できないテキストを含む PDF ドキュメントを読み込みます。このような文書は、通常、文書をスキャンし、その文書を Adobe Acrobat PDF 形式で保存することによって作成されます。 (サンプル文書で練習したい場合は、参考文献を参照してください。)
ステップ 3
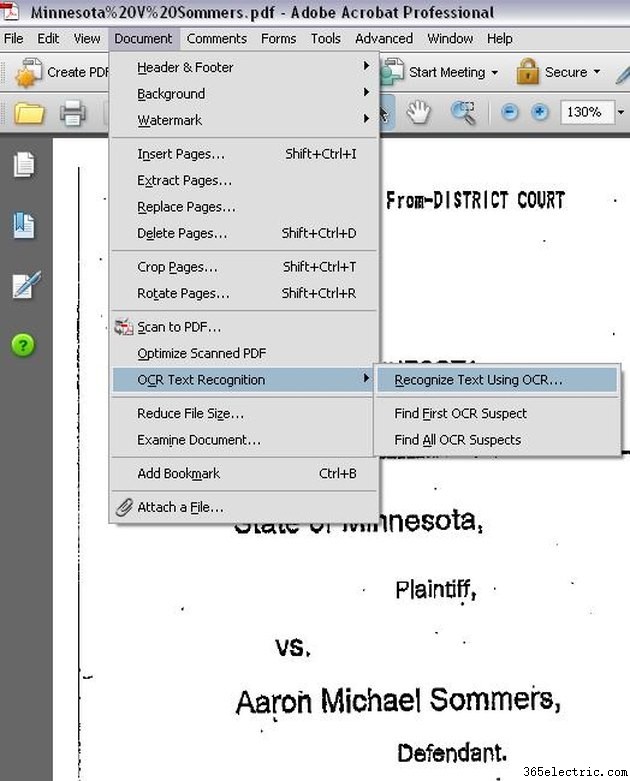
ドキュメントに対して OCR を実行します。 Adobe Acrobat Professional で、[ドキュメント] メニューをクリックし、[OCR テキスト認識] を選択してから、[OCR を使用してテキストを認識] をクリックします。
ステップ 4
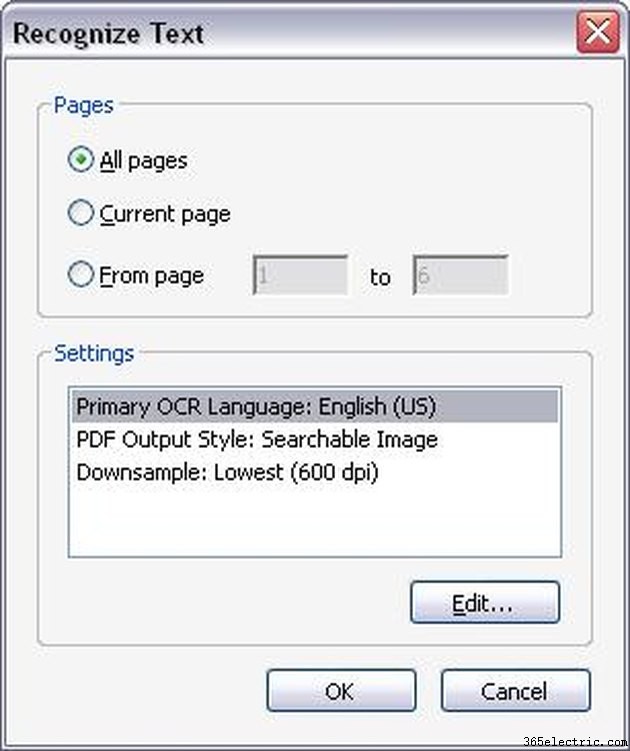
該当する OCR オプションを選択します。 [OCR を使用してテキストを認識する] をクリックすると、新しいウィンドウがポップアップ表示され、OCR を実行するページ範囲を選択するよう求められます。 PDF ファイル全体に対して OCR を実行することも、OCR 認識を数ページのみに制限することもできます。 OCR を実行するページ数を選択したら、[OK] をクリックします。 Acrobat Professional は、文書のページ内のテキストを認識し始めます。
ステップ 5
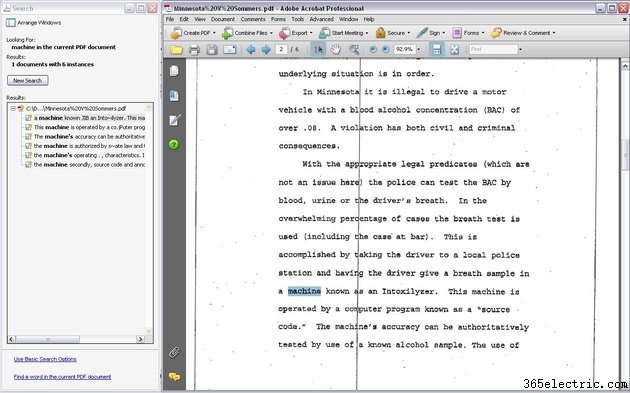
OCR が完了したらテキストを検索し、Microsoft Word から抽出した PDF と同じようにテキストをコピーして貼り付けます。ただし、OCR テクノロジは完全ではないことに注意してください。 OCR は特定の単語を正しく認識できず、一部のテキストを完全に見逃してしまう可能性があります。 OCR は、テキストの完全に鮮明な画像で最適に機能しますが、スキャンされたドキュメントでは常に可能とは限りません。